leetcode travel
算法
二分查找
二分查找比较简单, 是一种在有序数组中查找特定元素的搜索的办法
二分查找维基百科
二分查找的是时间复杂度是 O(log n) 次比较操作, n 是数组元素符号, log 是对数, 并使用常数空间,无论数据规模多大,使用的空间都是一样的,除非数据规模非常小,否则二分搜索比线性搜索快,但是数组必须是有顺序的.
704 二分查找
这是一个标准到不能在标准的二分查找题.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 var search = function (nums, target ) { if (nums.length === 0 ) { return -1 ; } if (nums.length === 1 ) { if (nums[0 ] === target) { return 0 ; } else { return -1 ; } } let l = 0 ; let r = nums.length - 1 ; while (l <= r) { const mid = Math .floor ((l + r) / 2 ); if (nums[mid] === target) { return mid; } else if (nums[mid] > target) { r = mid - 1 ; } else { l = mid + 1 ; } } return -1 ; };
35 搜索插入位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution : def searchInsert (self, nums: List [int ], target: int ) -> int : l = 0 r = len (nums) - 1 while l <= r: mid = (l + r) // 2 if nums[mid] < target: l = mid + 1 elif nums[mid] > target: r = mid - 1 elif nums[mid] == target: return mid return l
36 求有效的完全平方数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 var isPerfectSquare = function (num ) { if (num === 0 ) { return false ; } if (num <= 2 ) { return true ; } let l = 0 , r = Math .floor (num / 2 ); while (l <= r) { const mid = Math .floor ((l + r) / 2 ); const t = mid * mid; if (t === num) { return true ; } else if (t > num) { r = mid - 1 ; } else { l = mid + 1 ; } } return false ; };
374 猜数字 又是一个标准的二分查找题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution : def searchInsert (self, nums: List [int ], target: int ) -> int : l = 0 r = len (nums) - 1 while l <= r: mid = (l + r) // 2 if nums[mid] < target: l = mid + 1 elif nums[mid] > target: r = mid - 1 elif nums[mid] == target: return mid return l
分治算法
分治算法基本概念就是将一个复杂的问题分解成更多的相同或者相似的子问题,进而再将子问题分解为更小的子问题,直到得到一个可以直接求解的简单问题
而适用分治算法的情况主要有以下几个特征:
问题的规模缩小到一定情况就很容易解决
问题可以被分解为规模较小的相同问题,具有最优子结构
利用子问题的解可以合并为该问题的解
问题所分解的各个问题是独立的,子问题之间不包含公共的子问题
一般而言分治算法的基本步骤如下:
分解 将问题分解为若干规模 相互独立 与原问题相同的子问题
解决 若子问题可以直接被解决 否则继续分解
合并 将各个子问题的解合并为原问题的解
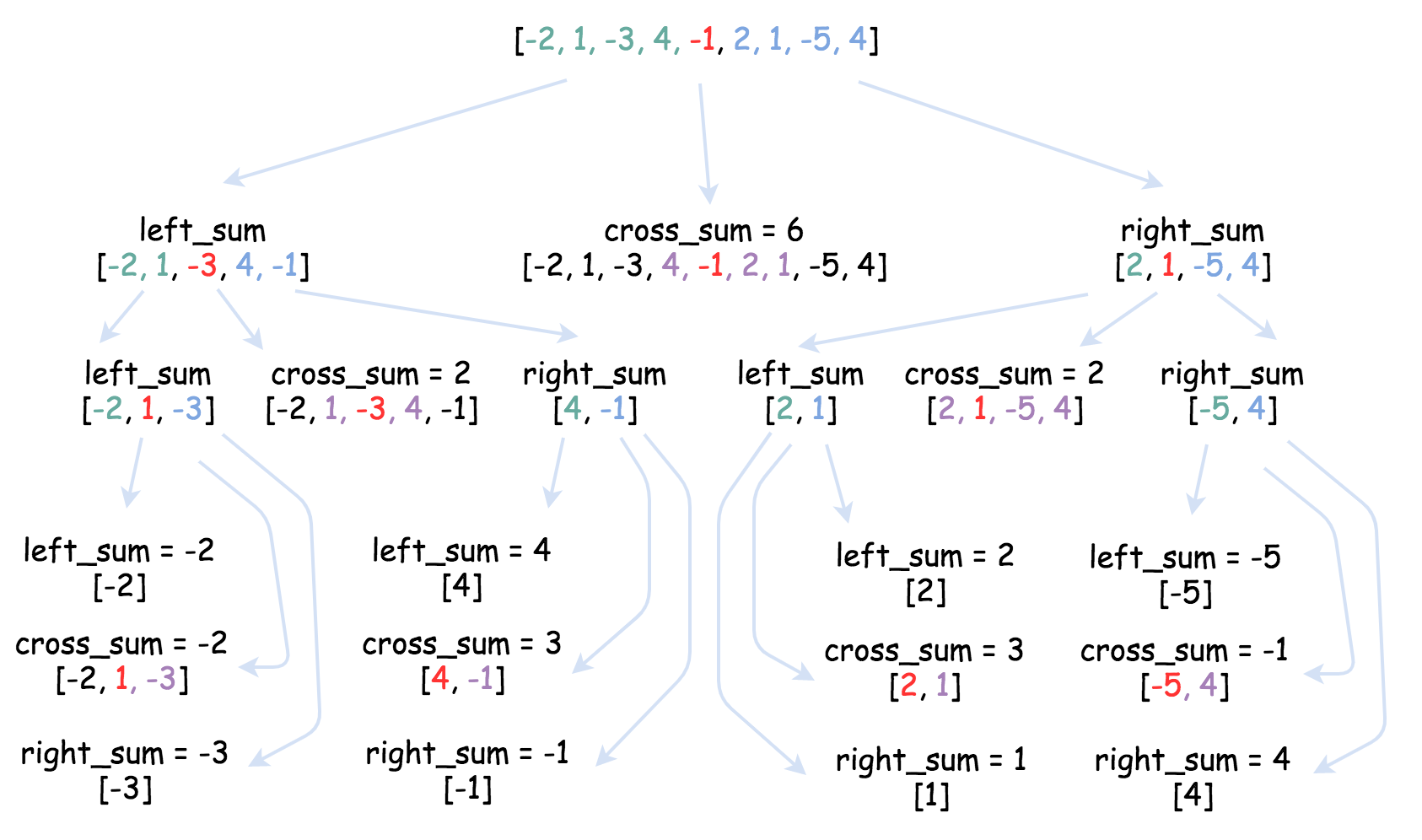
leetcode 多数元素
leetcode 有这个图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 var findKthLargest = function (nums, k ) { const MergeSort = (l, r ) => { if (l === r) return [nums[l]]; const mid = Math .floor ((l + r) / 2 ); const left = MergeSort (l, mid); const right = MergeSort (mid + 1 , r); const result = []; let idxL = 0 ; let idxR = 0 ; let index = 0 ; while (idxL <= left.length && idxR < right.length ) { if (left[idxL] > right[idxR]) { result[index] = left[idxL]; idxL++; } else { result[index] = right[idxR]; idxR++; } index++; } while (idxL < left.length ) { result[index] = left[idxL]; idxL++; index++; } while (idxR < right.length ) { result[index] = right[idxR]; idxR++; index++; } return result; }; return MergeSort (0 , nums.length - 1 )[k - 1 ]; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 ''' 这个算法 过不了 LeetCode 他有一个5000元素的数组,但是会直接超时,超过递归最大深度 ''' class Solution : def findKthLargest (self, nums: List [int ], k: int ) -> int : self .sort(nums, 0 , len (nums) - 1 ) return nums[k - 1 ] def partition (self, array: List [int ], L: int , R: int ): if (L == R): return pivot = array[R] partitionIndex = L index = L while (index < R): if (array[index] > pivot): array[partitionIndex], array[index] = array[index], array[partitionIndex] partitionIndex += 1 index += 1 array[partitionIndex], array[index] = array[index], array[partitionIndex] return partitionIndex def sort (self, array: List [int ], L: int , R: int ): if (L < R): partitionIndex = self .partition(array, L, R) self .sort(array, L, partitionIndex - 1 ) self .sort(array, partitionIndex + 1 , R)
240 搜索二维矩阵
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 var searchMatrix = function (matrix, target ) { const search = (list, l, r ) => { if (list.length === 0 ) return false ; if (l === r) return list[l] === target; const mid = Math .floor ((l + r) / 2 ); if (list[mid] === target) { return true ; } if (target > list[mid]) { return search (list, mid + 1 , r); } return search (list, l, mid); }; for (let index = 0 ; index < matrix.length ; index++) { if (search (matrix[index], 0 , matrix[index].length - 1 )) { return true ; } } return false ; }; `` ` ## 动态规划 根据维基百科上的定义,动态规划背后的基本思想非常简单,和分治思想很相同,给定一个问题,分解为若干小问题,然后再根据子问题的解,来求得原问题的解。 和分治类似,动态规划法试图每次只解决一个子问题,从而减少计算量,和分治算法不同的是,动态规划会记录已经得到解答的子问题的解,以便下次直接求值得时候直接返回记录的值。 根据 [stackoverflow](https://stackoverflow.com/questions/13538459/difference-between-divide-and-conquer-algo-and-dynamic-programming) 回答了动态规划和分治法之之间的区别和联系,可以简单地理解为动态规划是一种优化过的分治算法。 fibonacci 算法中分治算法和动态规划算法的区别 一般分治法的递归斐波那契函数  使用动态规划的斐波那契函数  动态规划的优势在于会缓存已经计算过的结果,从而提高速度。 [leetcode 区域和检索-数组不可变](https://leetcode-cn.com/problems/range-sum-query-immutable/solution/qu-yu-he-jian-suo-shu-zu-bu-ke-bian-by-leetcode/) 这个题目说了会多次调用 sumRange 方法,所以就可以使用动态规划方法,缓存结果,多次运行之后就会提高命中结果,节约时间,以空间换时间 [121. 买卖股票的最佳时机](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/submissions/) 使用了双层循环时间复杂度约为 O(n^2) 空间复杂度为常数,只使用了一个变量 ` `` javascriptvar maxProfit = function (prices ) { if (prices.length <= 1 ) return 0 ; let sum = 0 ; for (let i = 0 ; i < prices.length ; i++) { for (let j = i + 1 ; j < prices.length ; j++) { if (prices[i] < prices[j]) { sum = Math .max (prices[j] - prices[i], sum); } } } return sum; };
如何使用动态规划来解决这个问题,可以极大的减少时间复杂度,只需要付出一点空间即可
1 2 3 4 5 6 7 8 9 10 11 12 class Solution : def maxProfit (self, prices: List [int ] ) -> int : sum = 0 low = float ("inf" ) for i in range (len (prices)): if (prices[i] < low): low = prices[i] else : sum = max (sum , prices[i] - low) return sum
70. 爬楼梯
这个题本来没什么思路,之后看了答案,发现答案是有规律的
阶数
方法数
1
1
2
2
3
3
4
5
5
8
6
13
7
21
8
34
9
55
10
89
设:阶数为 N 那么 N = N-1 + N- 2
1 2 3 4 5 6 7 8 9 10 var climbStairs = function (n ) { if (n === 1 ) return 1 ; if (n === 2 ) return 2 ; const list = [1 , 2 ]; for (let index = 2 ; index < n; index++) { list[index] = list[index - 1 ] + list[index - 2 ]; } return list[n - 1 ]; };
这里通过维护一个数组,来记录结果,时间复杂度为 O(n) 空间复杂度 O(n)
实际上只需要维护 N+1 和 N+2 的值就可以了,不需要保留其他的值那么通过优化就可以得到如下代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public : int climbStairs (int n) if (n == 1 ) return 1 ; if (n == 2 ) return 2 ; int t = 1 , z = 2 ; size_t index = 2 ; while (index < n) { int tmp = t + z; t = z; z = tmp; index ++; } return z; } };
使用最小花费爬楼梯
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var minCostClimbingStairs = function (cost ) { let t = 0 , z = 0 ; let index = 0 ; while (index < cost.length ) { const tmp = cost[index] + Math .min (t, z); t = z; z = tmp; index++; } return Math .min (t, z); };
动态规划的核心是找到状态转移方程,根据方程来实现算法.
贪心算法
贪心算法(贪婪算法),是一种在每一步选择中都采用当前状态下最好或者最优的选择,从而希望导致结果是最好或最优呃算法。
贪心算法在具有最优结果的问题中尤为有效,最优子结构的意思是局部最优解决能决定全局最优解。
贪心算法于动态规划的不用在于它对每个子问题的解决方案都做出选择,不能回退,动态规划则会保存以前的运算结果,根据以前的结果对当前的进行选择,有回退功能。
860. 柠檬水找零
这题看别人讲解说找零的时候优先使用 10 块,用不了 10 块才用 5 块,这里使用了贪心
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 var lemonadeChange = function (bills ) { let five = 0 , ten = 0 ; for (let i = 0 ; i < bills.length ; i++) { if (bills[i] === 5 ) { five += 1 ; } else if (bills[i] === 10 ) { if (five === 0 ) { return false ; } five -= 1 ; ten += 1 ; } else { if (ten !== 0 && five !== 0 ) { ten -= 1 ; five -= 1 ; } else if (five > 2 ) { five -= 3 ; } else { return false ; } } } return true ; };
1005. K 次取反后最大化的数组和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 var largestSumAfterKNegations = function (A, K ) { let index = 0 ; let k = K; while (index < K) { let minIndex = 0 ; for (let j = 1 ; j < A.length ; j++) { if (A[minIndex] > A[j]) { minIndex = j; } } if (A[minIndex] < 0 ) { A[minIndex] = -A[minIndex]; k -= 1 ; index++; } else { if (k >= 2 ) { k -= 2 ; index += 2 ; } else { A[minIndex] = -A[minIndex]; k -= 1 ; index++; } } } return A.reduce ((res, cur ) => { res += cur; return res; }, 0 ); };
1282. 用户分组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 var groupThePeople = function (groupSizes ) { if (groupSizes === 0 ) return []; const hashMap = new Map (); for (let i = 0 ; i < groupSizes.length ; i++) { if (hashMap.has (groupSizes[i])) { const t = hashMap.get (groupSizes[i]); t.push (i); hashMap.set (groupSizes[i], t); } else { hashMap.set (groupSizes[i], [i]); } } const result = []; hashMap.forEach ((value, key ) => { if (value.length <= key) { result.push (value); } else { let i = 0 ; while (i < value.length ) { result.push (value.slice (i, i + key)); i += key; } if (i < value.length ) { result.push (value.slice (i, value.length )); } } }); return result; };
回溯算法
回溯算法是暴力搜索搜索法中的一种, 对于某些计算问题而言,回溯法是一种可以找出所有(或者一部分)解的一般性算法,尤其适用于约束满足性问题,其中最有名的八皇后问题,就展示了回溯算法的用例.
回溯算法维基百科
784 字母大小写排列
有点丑陋的代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 var letterCasePermutation = function (S ) { const res = []; const helper = (s, S, l, res ) => { res.push (s); for (let i = l; i < S.length ; i++) { if ( S[i] >= "a" && S[i] <= "z" ) { helper ( s.substring (0 , i) + S[i].toUpperCase () + S.substring (i + 1 , S.length ), S, i + 1 , res ); } else if (S[i] >= "A" && S[i] <= "Z" ) { helper ( s.substring (0 , i) + S[i].toLowerCase () + S.substring (i + 1 , S.length ), S, i + 1 , res ); } } }; helper (S, S, 0 , res); return res; };
数据结构
栈
栈是一种抽象类型, 指只允许在有序的线性集合的一端,加入数据和移除数据的操作,按照先进后出的原理运作(队列使用先进先出).
1047. 删除字符串中的所有相邻重复项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 var removeDuplicates = function (S ) { const res = []; for (let i = 0 ; i < S.length ; i++) { if (res.length === 0 ) { res.push (S[i]); } else { if (res[res.length - 1 ] === S[i]) { res.pop (); } else { res.push (S[i]); } } } return res.reduce ((s, c ) => s + c, "" ); };
921. 使括号有效的最少添加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 var minAddToMakeValid = function (S ) { const stack = []; for (let i = 0 ; i < S.length ; i++) { if (S[i] === "(" ) { stack.push (S[i]); } else { if (stack.length !== 0 && stack[stack.length - 1 ] === "(" ) { stack.pop (); } else { stack.push (S[i]); } } } return stack.length ; };
946. 验证栈序列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 var validateStackSequences = function (pushed, popped ) { if (pushed.length !== popped.length ) return false ; const stack = []; let j = 0 ; for (let i = 0 ; i < pushed.length ; i++) { stack.push (pushed[i]); while (stack.length !== 0 && popped[j] === stack[stack.length - 1 ]) { stack.pop (); j++; } } return j === popped.length ; };
链表
链表是一种线性表, 特性是可以在插入和删除的时候达到 O(1) 的复杂度, 但是查找和访问指定编号的节点则需要 O(n) 的时间, 不支持随机访问.
1290. 二进制链表转整数
1 2 3 4 5 6 7 8 var getDecimalValue = function (head ) { let res = "0b" ; while (head) { res += head.val ; head = head.next ; } return Number (res); };
141. 环形链表
使用快慢指针, 如果链表不存在环,那么快指针一定先到达结尾,相反如果存在环,那么慢指针就会在某一点与快指针相交
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 var hasCycle = function (head ) { if (!head || head.next === null ) { return false ; } let slow = head, fast = head.next ; while (slow !== fast) { if (fast === null || fast.next === null ) { return false ; } slow = slow.next ; fast = fast.next .next ; } return true ; };
树
维基百科 树
四种主要的遍历思想为:
前序遍历:根结点 —> 左子树 —> 右子树
中序遍历:左子树—> 根结点 —> 右子树
后序遍历:左子树 —> 右子树 —> 根结点
938. 二叉搜索树的范围和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 var rangeSumBST = function (root, L, R ) { const stack = [root]; let res = 0 ; while (stack.length ) { let node = stack.pop (); if (node !== null ) { if (node.val >= L && node.val <= R) { res += node.val ; } if (node.val > L) { stack.push (node.left ); } if (node.val < R) { stack.push (node.right ); } } } return res; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution : def rangeSumBST (self, root: TreeNode, L: int , R: int ) -> int : self .res = 0 self .helper(root, L, R) return self .res def helper (self, node: TreeNode, L: int , R: int ): if (node != None ): if node.val >= L and node.val <= R: self .res += node.val if node.val > L: self .helper(node.left, L, R) if node.val < R: self .helper(node.right, L, R)
617. 合并二叉树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 var mergeTrees = function(t1, t2) { const stack = [[t1, t2]]; while (stack.length) { let node = stack.pop(); if (node[0] === null || node[1] === null) { continue; } node[0].val += node[1].val; if (node[0].left === null) { node[0].left = node[1].left; } else { stack.push([node[0].left, node[1].left]); } if (node[0].right === null) { node[0].right = node[1].right; } else { stack.push([node[0].right, node[1].right]); } } return t1 === null ? t2 : t1; };
1 2 3 4 5 6 7 8 9 class Solution : def mergeTrees (self, t1: TreeNode, t2: TreeNode ) -> TreeNode: if not t1 and t2: return t2 elif t1 and t2: t1.val = t2.val+t1.val t1.left = self .mergeTrees(t1.left,t2.left) t1.right = self .mergeTrees(t1.right,t2.right) return t1
226. 翻转二叉树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 var invertTree = function (root ) { const stack = [root]; while (stack.length ) { const node = stack.pop (); if (node) { const tmp = node.left ; node.left = node.right ; node.right = tmp; stack.push (node.left ); stack.push (node.right ); } } return root; };
1 2 3 4 5 6 7 8 9 10 11 12 class Solution : def invertTree (self, root: TreeNode ) -> TreeNode: if (root == None ): return [] if (root): root.right, root.left = root.left, root.right self .invertTree(root.left) self .invertTree(root.right) return root
104. 二叉树的最大深度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 var maxDepth = function (root ) { if (root === null ) { return 0 ; } let res = 0 ; const stack = [[root, 1 ]]; while (stack.length ) { const [node, deep] = stack.pop (); if (node !== null && node.val !== null ) { res = Math .max (deep, res); stack.push ([node.left , deep + 1 ]); stack.push ([node.right , deep + 1 ]); } } return res; };
1 2 3 4 5 6 7 8 9 10 class Solution : def maxDepth (self, root: TreeNode ) -> int : if (root == None ): return 0 leftDeep = self .maxDepth(root.left) rightDeep = self .maxDepth(root.right) return max (leftDeep, rightDeep) + 1
589. N叉树的前序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var preorder = function (root ) { if (!root) return []; var res = []; function recusion (root, res ) { if (!root) return ; res.push (root.val ); for (var i = 0 ; i < root.children .length ; i++) { recusion (root.children [i], res); } } recusion (root, res); return res; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution : def preorder (self, root: 'Node' ) -> List [int ]: if root == None : return [] stack, output = [root], [] while stack: node = stack.pop() if node != None : output.append(node.val) if node.children: stack.extend(node.children[::-1 ]) return output
700. 二叉搜索树中的搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 var searchBST = function (root, val ) { if (root === null ) return []; if (root.val === val) return root; if (root.val !== val && root.left === null && root.right === null ) return null ; const stack = [root]; while (stack.length ) { const node = stack.pop (); if (node !== null ) { if (node.val === val) return node; stack.push (node.left ); stack.push (node.right ); } } return null ; }; var searchBST = function (root, val ) { if (root === null ) return []; if (root.val === val) return root; if (root.val !== val && root.left === null && root.right === null ) return null ; let node = root; while (node) { if (node === null ) { return null ; } if (val === node.val ) { return node; } if (val < node.val ) { node = node.left ; continue ; } else { node = node.right ; continue ; } } return null ; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution : def searchBST (self, root: TreeNode, val: int ) -> TreeNode: if (root == None ): return None if (root.val == val): return root if (val < root.val): return self .searchBST(root.left, val) elif val > root.val: return self .searchBST(root.right, val) else : return None
breadth-first-search(广度优先搜索)
参考资料 JavaScript 参考资料 python